

Your platform is cloud-native. CI/CD is in place. Infra is codified. Yet, release day still feels uncertain. In 2025, most teams won’t be struggling with missing DevOps tools. They are struggling with gaps in integration, visibility, precise monitoring and alerting with quick feedback, quick incident Detection and Response, and control at scale.
If your product delivery feels like this, you are not alone:
- Internal platforms exist, but developers find them hard to use or avoid them altogether
- GitOps is in play, but the live environment doesn’t always match what’s in Git
- Standard deployment practices (“golden paths”) are defined, but not consistently followed
- AI-assisted development has sped up coding, but pipelines weren’t designed to handle the new pace
- Monitoring tools generate alerts, but lack the context to drive real action
- Incident response involves too many handoffs between teams, slowing down recovery
- Approvals and compliance checks still block releases at the last mile
- Tool sprawl has created complex workflows that slow down rather than speed up delivery
- Security scans surface hundreds of critical or high-severity issues with no prioritization—so teams ignore them altogether
These challenges aren’t due to a lack of maturity—they are signs your DevOps approach needs to evolve with your scale and complexity.
Today’s DevOps is about more than automation. It’s about:
- Building platforms that are easy for developers to adopt
- Connecting delivery, observability, and incident response
- Automating smarter, with built-in context and safety
- Improving speed without compromising control
A recent trend shows a strong correlation between the number of DevOps technologies used by developers and their likelihood of being a top performer. Leveraging the right combination of tools effectively contributes to greater resilience and velocity.
If your delivery process feels like it should be smoother by now, it’s probably time to revisit your DevOps strategy. In 2025, these aren’t junior mistakes—they are signals that your DevOps strategy hasn’t kept pace with scale, complexity, and velocity.
The DevOps Mindset: Beyond Automation
DevOps isn’t just CI/CD or pipeline automation. It’s a mindset of shared responsibility, continuous feedback, and platform reliability. You are aligning people, practices, and platforms to enable repeatable, reliable, and scalable product delivery.
A DevOps-first mindset can:
- Eliminate release anxiety and post-deployment chaos
- Slash deployment failure rates
- Significantly cut lead time for changes—from commit to production
- Move teams from quarterly to weekly or even daily releases
- Reduce the time to roll back from hours to minutes
- Free engineers from firefighting to focus on building new features
- Build reliable, repeatable infrastructure using automation and codified provisioning
- Enable faster incident detection and response through integrated monitoring and alerting
- Turn deployment into a non-event—quiet, consistent, and continuous
What Are DevOps Frameworks?
DevOps frameworks are structured models that combine principles, practices, tools, and governance to help organizations adopt and scale modern software delivery. These frameworks provide a consistent approach to building resilient, automated, and secure delivery pipelines—across teams and environments.
More than just process enablers, mature DevOps frameworks embed Governance, Risk, and Compliance (GRC) into the development lifecycle. This ensures that speed doesn’t come at the cost of security or regulatory alignment.
A strong DevOps framework helps you:
- Align delivery goals with business and compliance objectives
- Standardize practices across teams, tools, and cloud environments
- Integrate Infrastructure as Code (IaC), CI/CD, observability, and security by design
- Incorporate GRC controls for auditability, policy enforcement, and risk mitigation
- Track DevOps maturity with KPIs and milestone checkpoints
- Move from reactive automation to an operationally governed, continuous delivery platform
Infrastructure as Code (IaC): Delivering Consistency at Scale
Inconsistent environments are one of the biggest sources of deployment pain. Infrastructure as Code (IaC) replaces manual setup and enables software development teams to define and manage infrastructure using code.
Benefits of Infrastructure as Code:
- Consistency: Environments are created from the same templates, eliminating configuration drift.
- Repeatability: You can spin up test, staging, and production environments on demand, confident that they will be identical.
- Speed: Automated infrastructure provisioning drastically reduces lead time for new environments.
- Auditability: Changes are tracked in version control, providing a clear history and supporting compliance needs.
- Recovery: If a deployment fails, environments can be destroyed and rebuilt quickly, ensuring minimal downtime.
Some of the widely adopted Infrastructure as Code tools include Terraform, AWS CloudFormation, ARM Templates, Bicep, and Ansible. These tools bring structure, governance, and compliance to cloud provisioning with robust automation capabilities.
CI/CD Implementation: Automating the Path to Production
CI/CD practices form the foundation of modern software delivery, enabling teams to streamline the build, test, and deployment cycle through automated pipelines.
How CI/CD Implementation Works:
Continuous Integration (CI):
- Engineers regularly push code updates to a centralized version control system, promoting continuous collaboration and integration.
- Automated build and test processes validate each commit.
- Issues are caught early, reducing the cost and complexity of fixes.
- Integrated security with shift-left approach.
Continuous Delivery (CD):
- Your code must automatically pass all tests to prepare for staging or production deployment.
- Manual approval may be required before production deployment (Continuous Delivery).
Continuous Deployment:
- Any code changes that pass through the automated tests get deployed to production without human intervention.
- Enables rapid iteration and reduces time-to-market.
Benefits of CI/CD Implementation:
- Reliability: Automation in CI/CD workflows helps minimize manual mistakes and ensures consistent delivery outcomes.
- Speed: Features, bug fixes, and patches reach customers faster.
- Quality: Integrated automated testing (unit, integration, regression) catches issues early in the pipeline, ensuring higher code quality with every release.
- Security: Built-in security checks—like SAST (Static Application Security Testing), DAST (Dynamic Application Security Testing), and secret scanning—help detect vulnerabilities before code reaches production.
- Safety: Rollbacks are automated and non-disruptive if something goes wrong.
- Scalability: Teams can deploy multiple times daily, supporting modern agile workflows.
Modern teams power their CI/CD engines with GitHub Actions, GitLab, ArgoCD, Jenkins, Helm, or Spinnaker.
Designing for Failure: Progressive and Predictable Recovery
Even the best pipelines can’t prevent every failure. What matters is how fast you detect, respond, and recover. In 2025, recovery must be automated, transparent, and safe. Progressive delivery models like canary, blue-green, and rolling deployments allow teams to test changes on a small slice of traffic before going wide.
Even with mature DevOps practices, occasional deployment failures are inevitable, especially in complex systems. While safe deployment techniques and a robust CI/CD pipeline minimize the likelihood of failures, organizations must also standardize their response to issues.
A progressive exposure deployment model—such as blue-green, canary, or rolling deployments—lays the foundation for minimizing user impact. However, having a well-defined deployment failure mitigation strategy ensures your teams can respond efficiently and transparently.A comprehensive mitigation strategy typically includes five key phases:
- Detection: Early identification is critical. Failures can surface through automated smoke tests, observability alerts (via Prometheus or Datadog), or user reports.
- Decision: The team must assess the severity and determine the appropriate response—rollback, roll-forward, hotfix, or feature flag adjustment.
- Mitigation: Execute the chosen action, such as reverting to a previous version, applying a runtime patch, or isolating the issue via configuration changes.
- Communication: Internal and external stakeholders (e.g., business teams and end-users) must be informed as per the incident response plan, often via Slack, StatusPage, or internal dashboards.
- Postmortem: Conducting a blameless postmortem helps teams capture learnings, identify root causes, and apply systemic improvements.
This structured approach ensures that deployment failures are contained, addressed swiftly, and turned into opportunities for continuous improvement.
Building Your DevOps Maturity Roadmap
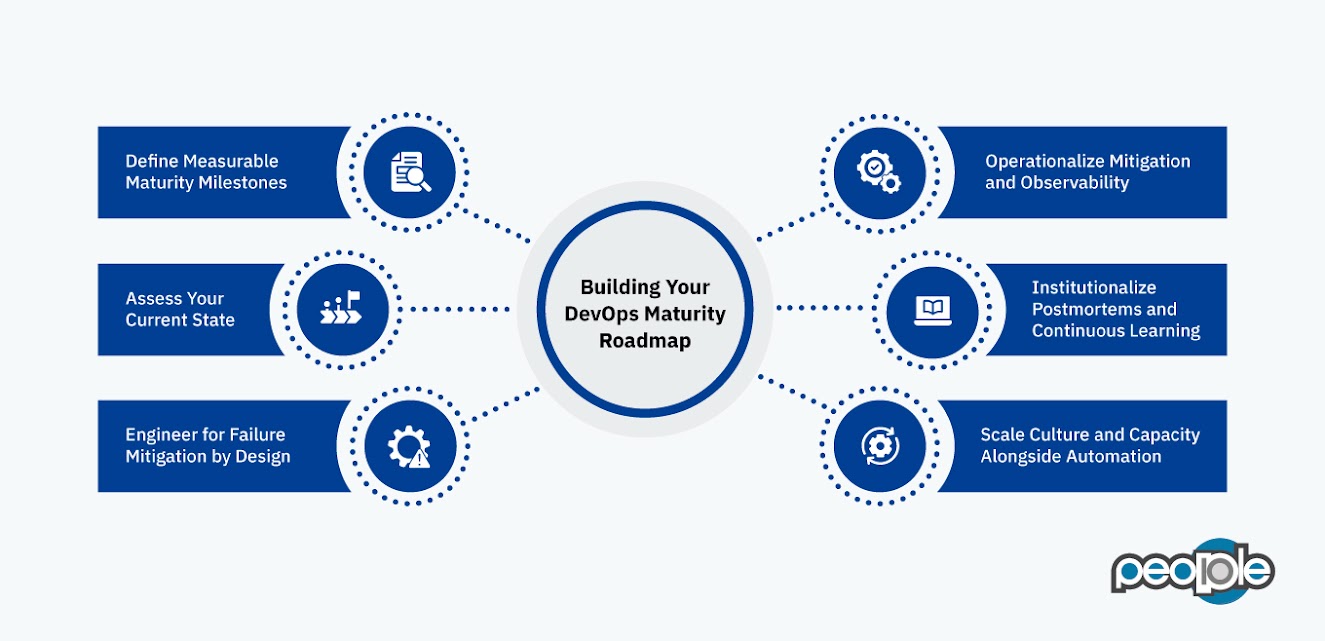
Mature DevOps isn’t built in a sprint—it’s engineered over time. And DevOps transformation isn’t a checklist. It’s an ongoing maturity journey that requires thoughtful sequencing, engineering discipline, and alignment with business-critical goals.
To move from ad hoc deployments to a mature, scalable DevOps model that can withstand failures and support continuous innovation, organizations must focus on six pillars:
1. Assess Your Current State
Start with a thorough audit of your software delivery lifecycle:
- How frequent are your deployments?
- How often do production changes fail?
- How long do planned changes take to reach production—from conception to deployment—on average?
- What percentage of your deployment steps are still manual?
- How do you detect and handle deployment failures?
- Are your environments truly consistent (immutable vs. mutable)?
- Can you roll back, fall back, or bypass issues systematically?
In parallel, assess:
- Team structure and handoff inefficiencies
- Tooling fragmentation across stages
- Deployment latency across business-critical workloads
This baseline will help identify gaps that are slowing down speed, increasing risk, or undermining reliability.
2. Define Measurable Maturity Milestones
Set clear, outcome-driven KPIs:
- Deployment failure rate <5%
- Mean time to recovery (MTTR) <15 minutes
- 90% of infrastructure managed via IaC
- 100% of deployments under progressive exposure models (e.g., canary, blue-green)
- Automated rollback and runtime mitigation coverage for all tier-1 workloads
Your DevOps roadmap should map these targets to a capability, an owner, and a timeline.
3. Engineer for Failure Mitigation by Design
Failure is inevitable, even in mature environments. The goal is graceful degradation, fast containment, and minimal user impact. Standardize strategies based on workload type and infrastructure model:
- Rollback: Revert systems to last-known-good states. Plan for schema-safe rollbacks with additive changes only.
- Fallback: Remove updated stacks from routing and direct traffic to non-updated environments—ideal for blue-green models.
- Bypass: Use feature flags or config toggles to disable problematic functionality temporarily.
- Roll Forward: A hotfix with accelerated pipelines can be viable if the fix is low-effort and the issue is clear.
- Automated Recovery: Test automatic rollback triggers within CI/CD tools like Azure DevOps or Spinnaker, but only after validating rollback readiness.
Embed these strategies in a codified decision tree, with clear stakeholder approvals and risk thresholds.
4. Operationalize Mitigation and Observability
Operational maturity means failure handling isn’t reactive—it’s orchestrated.
- Parameterize deployments so pipelines can target specific versions with predictable outcomes.
- Maintain consistency in data/config/secret state across rollback/fallbacks.
- Integrate real-time observability (Prometheus, Datadog, OpenTelemetry) with alerting and incident response protocols.
- Define incident communication cadences and stakeholder update playbooks, especially for customer-facing outages.
- Automate and test your deployment failure plan regularly using chaos engineering or fault injection.
5. Institutionalize Postmortems and Continuous Learning
Every failed deployment must trigger a blameless postmortem—not just a patch or quick fix.
Key questions to ask:
- What went wrong? Where did detection, mitigation, or alerting fall short?
- Was the rollback or fallback successful? Why or why not?
- Which processes, infrastructure components, or team dynamics contributed to the issue?
Avoid attributing failure to human error.
A core DevOps principle is this: if success depends on someone getting it right every time, there’s a missing process, test, or automation. Human error is a signal—not a root cause.
Postmortem outcomes should:
- Identify systemic gaps, not individual blame
- Feed improvements back into your pipelines and tooling
- Inform future SLOs, runbooks, and mitigation playbooks
- Ensure backlog items from failures are prioritized and tracked to closure
- When done right, postmortems become your most powerful tool for operational maturity.
6. Scale Culture and Capacity Alongside Automation
As your tooling and processes evolve, your teams must evolve with them. DevOps maturity depends not just on automation, but on how well your people can adopt, adapt, and extend it.
Focus areas include:
- Cross-train teams to handle both feature delivery and incident response
- Favor small, frequent changes over large, risky releases to reduce blast radius
- Invest in developer enablement—covering IaC, testing, GitOps, and observability practices
- Introduce self-service tooling to reduce dependency on central teams and empower developers to manage environments, deployments, and rollbacks confidently
- Budget for redundancy in both infrastructure and personnel to sustain delivery velocity during turnover or peak load
Scaling DevOps is as much about people and autonomy as it is about platforms and pipelines. Some tradeoffs are unavoidable. Maintaining dual environments for fallbacks or running mutable and immutable infra may increase costs. However, they are necessary to achieve zero-downtime goals for business-critical services.
DevOps maturity is about engineering for resilience, not just speed. As deployment velocity increases, so must your ability to detect, decide, and recover from failure—systematically and transparently. By mapping your roadmap to these principles, you reduce deployment risk and enable true agility, confidence, and innovation at scale.
