


As organizations scale and systems become more complex, traditional monitoring tools struggle to keep up. The need for smarter, faster incident management has never been greater. Enter Machine Learning in IT Operations (ML in IT Ops)—a game-changing technology that can help businesses improve uptime, enhance team efficiency, and scale operations intelligently.
In this article, we explore how ML is transforming IT operations, from improving incident detection to automating remediation. We will guide you through the benefits, challenges, and practical steps to get started with Machine Learning in IT Operations, so you can confidently plan for the future of your IT environment.
Let us get started.
From Reactive to Autonomous: The Rise of Machine Learning in IT Operations

In traditional IT operations, issues were addressed reactively—often after a problem had occurred. With Machine Learning in IT Operations, this process is flipped. Instead of waiting for systems to fail, ML allows for accurate predictions, helping you prevent issues before they occur and significantly reducing downtime.
By analyzing real-time data, machine learning models spot patterns and anomalies in system behavior, identifying potential disruptions before they escalate into major incidents. The result is quicker incident response, fewer disruptions, and a more resilient IT infrastructure.
Predicting Issues Before They Happen
Machine learning in IT operations enables systems to recognize abnormal behavior long before it escalates into a major incident. By analyzing historical data, usage trends, and real-time telemetry, these models forecast potential disruptions.
This proactive stance enables teams to address root causes early, thereby reducing downtime and preserving business continuity.
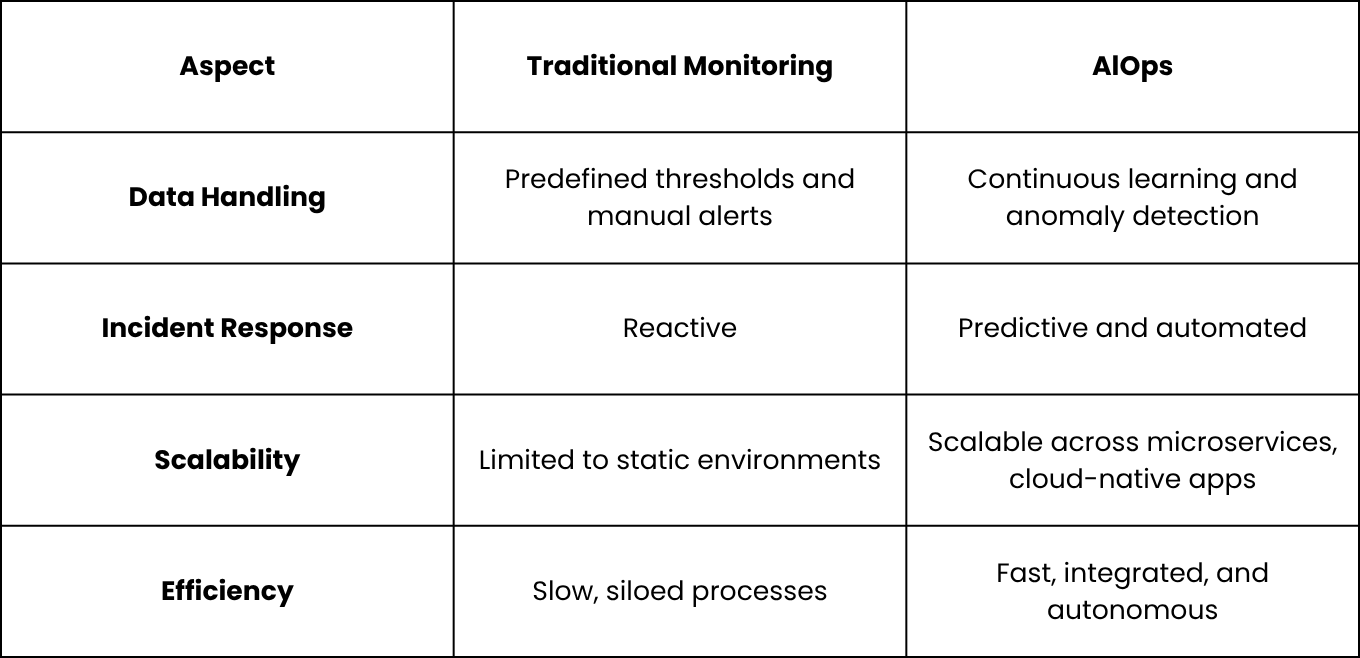
What Makes AIOps Different from Traditional Monitoring
Traditional monitoring tools rely on predefined rules and thresholds. For instance, they generate alerts only after something breaks or crosses a set limit.
In contrast, AIOps—powered by Machine Learning in IT Operations—goes far beyond surface-level signals. It continuously learns from evolving system behavior, correlates data across sources, and identifies anomalies without manual intervention.
This leads to faster root cause analysis, reduced noise, and smarter incident management.
For scaling organizations, AIOps offers a more adaptive and resilient foundation for modern IT operations.
How AIOps Enhances Incident Management
AIOps—Artificial Intelligence for IT Operations—uses Machine Learning to go beyond the limitations of traditional monitoring systems. Unlike older tools that rely on predefined rules and thresholds, AIOps continuously learns from evolving system behavior, correlates data across different sources, and identifies potential anomalies.
This leads to faster root cause analysis, reduced alert noise, and smarter, more efficient incident management. For companies experiencing rapid growth and increased IT complexity, AIOps provides a more adaptive, resilient foundation for IT operations. It shifts the focus from reactive to proactive, enabling faster decision-making and reducing the burden on IT teams.
Why Machine Learning in IT Operations Is Just Getting Started
The global AIOps (Artificial Intelligence for IT Operations) market was valued at USD 1.87 billion in 2024 and is projected to grow to USD 2.23 billion in 2025, reaching USD 8.64 billion by 2032, exhibiting a CAGR of 21.4% during the forecast period. Modern architectures—such as microservices, cloud-native apps, and distributed systems—generate large volumes of data that traditional monitoring tools are ill-equipped to handle. More teams are starting to see its value. Hence, systems are growing more complex, and microservices, cloud-native apps, and distributed architectures make it increasingly difficult to track everything manually.
Traditional monitoring tools were not built for this level of scale or speed. Manual triage is no longer enough. It is slow, inconsistent, and reactive. That is where Machine Learning in IT Operations steps in with real power. It can process millions of logs, metrics, and traces in real time. It identifies patterns and anomalies in real-time—context-aware, not just reactive.
No more chasing false positives. No more getting buried in noise. Now, your engineers can focus on solving real problems faster, smarter, and with less burnout. The shift is happening. And it is opening up a new era of intelligent, scalable operations.
Machine Learning in IT Operations: A 3-Phase Maturity Model
Adopting machine learning in IT operations can be approached in phases:
- Reactive: Traditional systems focused on responding after incidents occurred.
- Predictive: With AIOps, organizations start using ML to predict issues and prevent downtime before it happens.
- Autonomous: At this stage, ML-driven systems not only predict but also take action independently, making the IT operations environment self-healing and continuously improving.
The transition through these stages enables organizations to gradually unlock the full potential of ML, turning IT operations from a reactive state to a self-optimizing system.
Traditional Monitoring vs AIOps: A Quick Comparison
MLOps Meets DevOps: The Future of Machine Learning in IT Operations
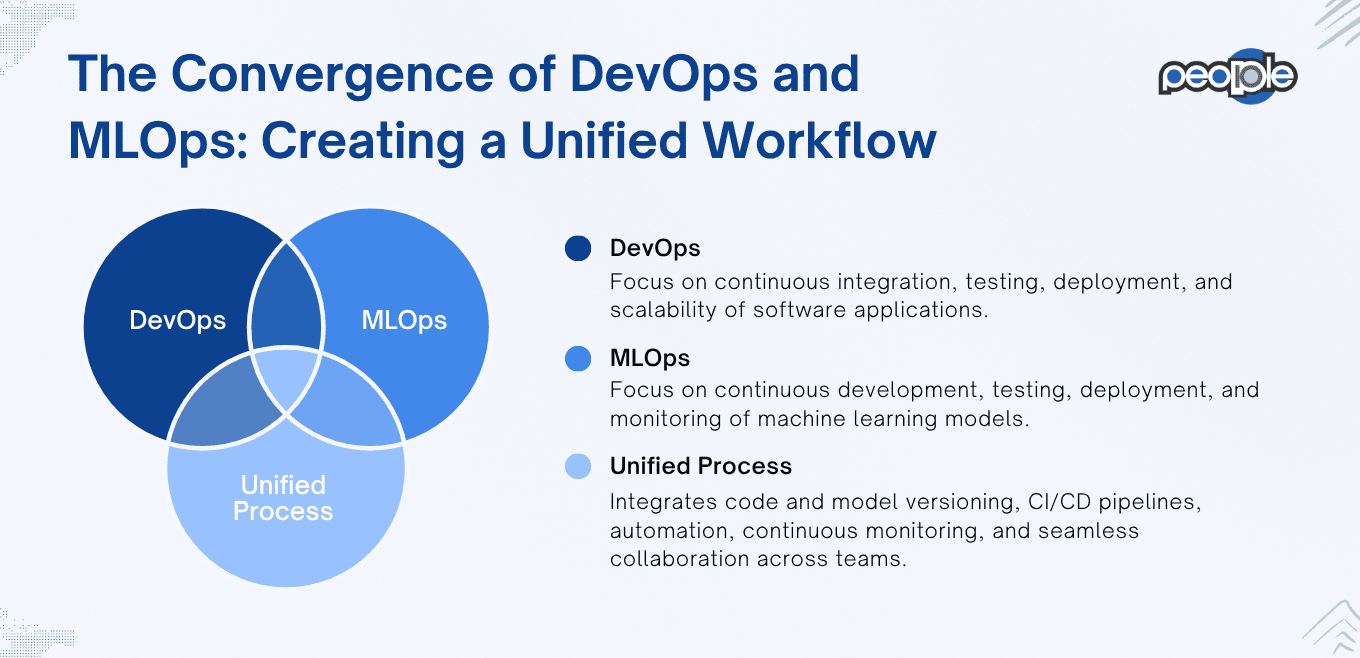
DevOps changed how we build and ship software. Now, MLOps is doing the same for ML models. But here is where it gets exciting: DevOps and MLOps are starting to merge.
When you bring them together, you create one seamless delivery pipeline. Code and models move from development to production with confidence. You reduce friction, increase velocity, and build trust across teams.
Let us examine the details of how it is happening.
Unifying Code and Model Pipelines
When you unify them into one seamless pipeline, you streamline the entire delivery process. Developers and data scientists work in sync. Updates move faster from experimentation to production.
Machine Learning in IT Operations makes this alignment possible. With shared version control, consistent deployment methods, and unified environments, handoffs become frictionless. No more lost files, mismatched environments, or confusing dependencies. Just clean, traceable, production-ready work.
Reducing Friction Across Teams
Great products are built by teams that work well together. However, ML workflows often create friction. Data scientists, developers, and operations speak different languages. Without the right processes, collaboration breaks down.
Machine Learning in IT Operations helps bridge that gap. With shared tooling, standardized processes, and clear responsibilities, everyone stays aligned. Models become part of the larger system—not an afterthought.
When teams stop stepping on each other’s toes, delivery speeds up. Everyone does their best work. And the product continues to improve, becoming better and faster.
CI/CD for Models and Why It Matters
CI/CD has changed how we ship code. Now, it is time to do the same for ML models. With proper CI/CD pipelines for models, you bring automation, testing, and control to a workflow that was often manual and fragile.
Machine Learning in IT Operations depends on this discipline. Models can now be trained, validated, and deployed with the same confidence as code. This means fewer bugs, faster rollbacks, and more reliable performance in production. That is not just efficiency—it is peace of mind.
Versioning and Monitoring in ML Workflows
What gets tracked gets improved.
ML workflows must be versioned just like software code. That includes datasets, training runs, model parameters, and deployment history. When something breaks in production, you need to know exactly what changed—and why.
Machine Learning in IT Operations enables this visibility. With proper versioning, you can roll back safely, compare experiments, and keep your models audit-ready.
Add monitoring, and now you have real-time feedback on model drift, accuracy, and performance. You stay in control, even long after deployment. That is how real businesses scale with confidence.
Explainability: Building Trust in Machine Learning in IT Operations
As Machine Learning in IT Operations becomes more autonomous, it starts making decisions that impact infrastructure, uptime, and user experience. That is why explainability is no longer optional. It is essential.
You need to understand why the system flagged a specific anomaly, triggered a response, or ignored a signal altogether. Without that clarity, teams hesitate. Stakeholders question outcomes. And trust breaks down.
Explainable AI (XAI) addresses this challenge head-on.
It reveals the reasoning behind the model decision: what data it used, how it interpreted patterns, and why it acted the way it did. This transparency builds confidence across the board.
You can review decisions, trace their logic, and identify any flaws. That means stronger audits, easier compliance, and a team that is not left guessing. And when models make mistakes, you can fix them faster with full visibility into what went wrong.
Why Explainability Matters
Because trust leads to adoption.
If your team does not understand how decisions are made, they will not rely on them. With explainability, you empower engineers, auditors, and leadership to validate results and improve processes.
It’s not just about visibility—it’s about control. You remain in charge, even as the system scales.
Tools for Understanding Model Decisions
Today’s platforms offer built-in tools to make models more transparent. From feature attribution and decision trees to visual dashboards and heatmaps—these tools simplify complex logic into human-readable insights.
They help teams compare versions, debug outputs, and ensure alignment with business rules. When combined with Machine Learning in IT Operations, explainability turns automation into accountable, actionable intelligence.
Responsible Automation with Machine Learning in IT Operations
Machine Learning in IT Operations brings speed, efficiency, and intelligence to tasks that were once manual and repetitive. But even the most advanced models are not immune to issues, which can distort outcomes.
Model drift can degrade performance like small errors that can compound into major failures.
That is why responsible automation matters. It’s not just about what you automate—it’s about how you manage and monitor it.
Building checks and balances into your systems ensures that automation remains accurate, ethical, and aligned with your business goals. That means putting safeguards in place from day one—not as an afterthought.
You need end-to-end observability. Every decision made by an automated system should be traceable. Every output should be measurable. And every failure should be a lesson that feeds back into improvement.
Keep a human in the loop. Automation should augment teams, not replace them. When people stay involved—reviewing results, validating edge cases, and refining models—you get smarter systems and better outcomes.
Regular audits are critical. They help catch bias, ensure compliance, and maintain trust as your models evolve. As you scale automation, you must scale accountability too.
Machine Learning in IT Operations is a force multiplier. When used responsibly, it amplifies your team’s impact while protecting against unintended risks. That is how you build systems that are not only fast—but also fair, transparent, and reliable.
The Challenges of Adopting Machine Learning in IT Operations
Every transformation brings its own set of challenges. Machine Learning in IT Operations is no exception.
While the benefits are clear—faster incident response, smarter automation, and improved system resilience—achieving them is not always straightforward.
One of the biggest hurdles is data quality.
Machine learning models are only as good as the data they are trained on. If your input is noisy, incomplete, or inconsistent, the output will be unreliable.
Poor data leads to false positives, missed alerts, and unpredictable behavior. Before you scale any ML initiative, you must first clean and structure your data foundation.
Another major challenge is tooling. Many IT teams still work with fragmented systems—one tool for logging, another for metrics, and yet another for automation. This creates blind spots and slows down response time.
To make Machine Learning in IT Operations truly effective, you need a unified platform. One that brings together observability, AIOps, model deployment, and continuous monitoring. When your tools work together, your teams can too.
Adoption also requires a mindset shift. It is not just about technology—it is about process, culture, and readiness to evolve. Teams must be trained. Workflows must adapt. And leadership must champion the shift from manual firefighting to intelligent automation.
The road may be complex, but the payoff is worth it. Overcoming these early challenges sets the stage for long-term success and builds a future-proof operations strategy powered by machine learning.
Closing the Skills Gap for Machine Learning in IT Operations
ML is not plug-and-play. Your team needs new skills, including data engineering, model validation, and continuous monitoring. That takes time and investment.
Leadership must buy in. You need clear goals, training programs, and a roadmap. It is not about tools—it is about readiness.
The Road Ahead: What CIOs and CTOs Can Do to Embrace Machine Learning in IT Operations
Start with a simple audit. What data are you already collecting? Where are the current pain points in your operations?
When that’s done, run a pilot, test anomaly detection or alert correlation, and show your quick wins. It’ll help you build internal champions.
Once that’s done, you expand and connect ML with your CI/CD pipeline, merging MLOps and DevOps workflows to monitor everything. The global machine learning market was estimated at USD 72.6 billion in 2024 and is projected to reach USD 419.94 billion by 2030, growing at a CAGR of 33.2% from 2025 to 2030.
Machine learning in IT operations is not a trend. It is a shift. We are transitioning from manual effort to intelligent automation.
You will see faster resolution times and lower costs as you start working with it. Eventually, your teams can finally focus on innovation instead of firefighting.
Author

Nandakumar excels in delivering diverse solutions from mobile apps to complex enterprise systems. At People10, he continues to drive success with a focus on customer satisfaction and innovative technology solutions.
